「 Kubernetes 」节点资源超卖
based on v1.24.10
背景
Kubernetes 设计原语中,Pod 声明的 spec.resources.requests 用于描述容器所需资源的最小规格,Kube-scheduler 会根据资源请求量执行调度流程,并在节点资源视图中扣除;spec.resources.limits 用于限制容器资源最大使用量,避免容器服务使用过多的资源导致节点性能下降或崩溃。Kubelet 通过参考 Pod 的 QoS 等级来管理容器的资源质量,例如 OOM 优先级控制等。Pod 的 QoS 级别分为 Guaranteed、Burstable 和 BestEffort,QoS 级别并不是显式定义,而是取决于 Pod 声明的 spec.resources.requests 和 spec.resources.limits 中 CPU 与内存。
而在实际使用过程中,为了提高稳定性,应用管理员在提交 Guaranteed 和 Burstable 这两类 QoS Pod 时会预留相当数量的资源缓冲来应对上下游链路的负载波动,在大部分时间段,服务的资源请求量会远高于实际的资源使用率。

为了提升集群资源利用率,应用管理员会提交一些 BestEffort QoS 的低优任务,来充分使用那些已分配但未使用的资源。即基于 Pod QoS 的服务混部(co-location)以实现 Kubernetes 节点资源的超卖(overcommitted)。

这种策略常用于容器服务平台的在离线业务混部,但是这种基础的混部方案存在一些弊端:
- 混部会带来底层共享资源(CPU、内存、网络、磁盘等)的竞争,会导致在线业务性能下降,并且这种下降是不可预测的
- 节点可容纳低优任务的资源量没有任何参考,即使节点实际负载已经很高,由于 BestEffort 任务在资源规格上缺少容量约束,仍然会被调度到节点上运行
- BestEffort 任务间缺乏公平性保证,任务资源规格存在区别,但无法在 Pod 描述上体现
设计思考
在基于 Pod QoS 混部实现的 Kubernetes 节点资源超卖方案中,所要解决的核心问题是如何充分合理的利用缓冲资源,即 request buffer 与 limit buffer。
其中,limit buffer 在 Kubernetes 设计中天然支持超卖,Pod 在声明 spec.resources.limits 时,不受集群剩余资源的影响,集群中 Pod limits 之和也存在超出节点资源容量的情况,limit buffer 部分的资源是共享抢占的;而 request buffer 部分的资源是逻辑独占的,也就是说 spec.resources.requests 的大小会决定 Pod 能否调度,进而直接影响到节点资源的使用率。
因此,节点资源超卖理念更多的是对 request buffer 如何充分利用的思考。
资源回收与超卖
资源回收是指回收业务应用已申请的,目前还处于空闲的资源,将其给低优业务使用。但是这部分资源是低质量的,不具备太高的可用性保证。

如图所示,reclaimed 资源代表可动态超卖的资源量,这部分需要根据节点真实负载情况动态更新,并以标准扩展资源的形式实时更新到 Kubernetes 的 Node 元信息中。低优任务可以通过在 spec.resources.requests 和 spec.resources.limits 中定义的 reclaimed 资源配置来使用这部分资源,这部分配置同时也会体现在节点侧的资源限制参数上,保证低优作业之间的公平性。
可回收资源的推导公式大致如下:
reclaimed = nodeAllocatable * thresholdPercent - podUsage - systemUsage
- nodeAllocatable — 节点可分配资源总量
- thresholdPercent — 预留水位比例
- podUsage — 高优任务 Pod 的资源使用量
- systemUsage — 系统资源真实使用量
弹性资源限制
原生的 BestEffort 应用缺乏资源用量的公平保证,而使用动态资源的 BestEffort 应用需要保证其 CPU 使用量被限制在其允许使用的合理范围内,避免在不同 QoS 混部的场景下对高优 Pod 的干扰,确保整机的资源使用率控制在安全水位之下。
考虑到 Kubelet cgroup manager 不支持接口扩展,所以需要借助 agent 类型的组件维护容器的 cgroup,同时在 CPU 竞争时也能按照各自声明量公平竞争。
社区成果
国内社区在节点资源超卖方面的落地思路整体相似,都是围绕弹性资源的回收、超卖与限制三个部分展开。无论是阿里 Koordinator、腾讯 Crane、华为 Volcano、字节 Katalyst 等开源项目,还是网易轻舟 NCS 和美团 LAR 等内部平台等都是类似的解决方案,它们的本质相同,只是在弹性资源结算方式等细节点上有所不同。
Koordinator
https://github.com/koordinator-sh/koordinator
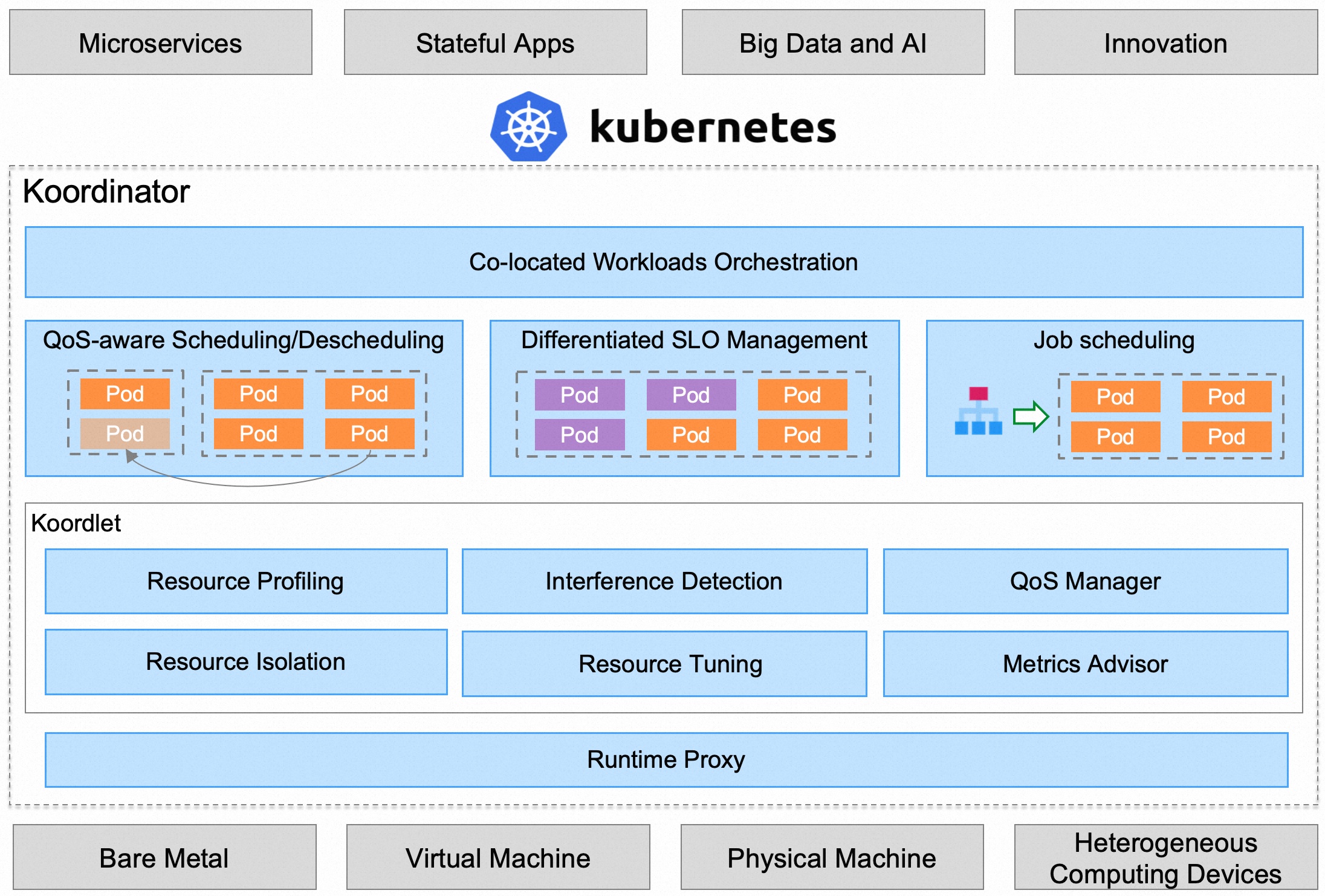
Koordinator 是一个基于 QoS 的 Kubernetes 混合工作负载调度系统,旨在提高对延迟敏感的工作负载和批处理作业的运行时效率和可靠性,简化与资源相关的配置调整的复杂性,并增加 Pod 部署密度以提高资源利用率。
SLO
在集群中运行的 Pod 资源 SLO(Service Level Objectives)由两个概念组成,即优先级和 QoS
- 优先级,即资源的优先级,代表了请求资源被调度的优先级。通常情况下,优先级会影响 Pod 在调度器待定队列中的相对位置
- QoS,代表 Pod 运行时的服务质量。如 cgroups cpu share、cfs 配额、LLC、内存、OOM 优先级等等
Koordinator 定义了五种类型的 QoS,用于编排调度与资源隔离场景:
| QoS | 特点 | 说明 |
|---|---|---|
| SYSTEM | 系统进程,资源受限 | 对于 DaemonSets 等系统服务,虽然需要保证系统服务的延迟,但也需要限制节点上这些系统服务容器的资源使用,以确保其不占用过多的资源 |
| LSE(Latency Sensitive Exclusive) | 保留资源并组织同 QoS 的 Pod 共享资源 | 很少使用,常见于中间件类应用,一般在独立的资源池中使用 |
| LSR(Latency Sensitive Reserved) | 预留资源以获得更好的确定性 | 类似于社区的 Guaranteed,CPU 核被绑定 |
| LS(Latency Sensitive) | 共享资源,对突发流量有更好的弹性 | 微服务工作负载的典型 QoS 级别,实现更好的资源弹性和更灵活的资源调整能力 |
| BE(Best Effort) | 共享不包括 LSE 的资源,资源运行质量有限,甚至在极端情况下被杀死 | 批量作业的典型 QoS 水平,在一定时期内稳定的计算吞吐量,低成本资源 |
此外,进一步定义了四类优先级,用于扩展优先级维度以对混部场景的细粒度支持:
| PriorityClass | 优先级范围 | 描述 |
|---|---|---|
| koord-prod | [9000, 9999] | 需要提前规划资源配额,并且保证在配额内成功 |
| koord-mid | [7000, 7999] | 需要提前规划资源配额,并且保证在配额内成功 |
| koord-batch | [5000, 5999] | 需要提前规划资源配额,一般允许借用配额 |
| koord-free | [3000, 3999] | 不保证资源配额,可分配的资源总量取决于集群的总闲置资源 |
弹性资源回收与超卖

Koordinator 的混部资源模型,其基本思想是利用那些已分配但未使用的资源来运行低优先级的 Pod。如图所示,有四条线:
- limit:灰色,高优先级 Pod 所请求的资源量,对应于 Kubernetes 的 Pod 请求。
- usage:红色,Pod 实际使用的资源量,横轴为时间线,红线为 Pod 负载随时间变化的波动曲线。
- short-term reservation:深蓝色,这是基于过去(较短)时期内的资源使用量,对未来一段时间内其资源使用量的估计。预留和限制的区别在于,分配的未使用(未来不会使用的资源)可以用来运行短期执行的批处理 Pod。
- long-term reservation:浅蓝色,与 short-term reservation 类似,但估计的历史使用期更长。从保留到限制的资源可以用于生命周期较长的 Pod,与短期的预测值相比,可用的资源较少,但更稳定。
Koordinator 的差异化 SLO 提供将这部分资源量化的能力。将上图中的红线定义为 usage,蓝线到红线预留部分资源定义为 buffered,绿色覆盖部分定义为 reclaimed。为体现与原生资源类型的差异性,Koordinator 使用 Batch 优先级的概念描述该部分超卖资源,也就是 batch-cpu 和 batch-memory。
节点中可超卖资源的计算公式为:
nodeBatchAllocatable = nodeAllocatable * thresholdPercent - podRequest(non-BE) - systemUsage
公式中的 thresholdPercent 为可配置参数,通过修改 ConfigMap 中的配置项可以实现对资源的灵活管理。
Pod 通过声明标准扩展资源的方式使用超卖资源:
1 | metadata: |
此外,Koordinator 提供了一个 ClusterColocationProfile CRD 和对应的 webhook 修改和验证新创建的 Pod,主要为 Pod 注入 ClusterColocationProfile 中声明的 Koordinator QoSClass、Koordinator Priority 等,以及将 Pod 申请的标准资源变更至扩展资源。工作流程如下:

弹性资源限制
Koordinator 在宿主机节点提供了弹性资源限制能力,确保低优先级 BE(BestEffort)类型 Pod 的 CPU 资源使用在合理范围内,保障节点内容器稳定运行。
在 Koordinator 提供的动态资源超卖模型中,reclaimed 资源总量根据高优先级 LS(Latency Sensitive)类型 Pod 的实际资源用量而动态变化,这部分资源可以供低优先级 BE(BestEffort)类型 Pod 使用。通过动态资源超卖能力,可以将 LS 与 BE 类型容器混合部署,以此提升集群资源利用率。为了确保 BE 类型Pod 的 CPU 资源使用在合理范围内,避免 LS 类型应用的运行质量受到干扰,Koordinator 在节点侧提供了 CPU 资源弹性限制的能力。弹性资源限制功能可以在整机资源用量安全水位下,控制 BE 类型 Pod 可使用的 CPU 资源量,保障节点内容器稳定运行。
如下图所示,在整机安全水位下(CPU Threshold),随着 LS 类型 Pod 资源使用量的变化(Pod(LS).Usage),BE 类型 Pod 可用的 CPU 资源被限制在合理的范围内(CPU Restriction for BE)。限制水位的配置与动态资源超卖模型中的预留水位基本一致,以此保证 CPU 资源使用的一致性。

Koordinator 支持通过 ConfigMap 配置弹性限制参数。
实践验证
以 Koordinator 为例
based on v1.2.0
使用 helm 安装
1 | Firstly add koordinator charts repository if you haven't do this. |
安装结果
1 | kubectl get all -n koordinator-system |
Koordinator 由两个控制面 Koordinator Scheduler、Koordinator Manager 和一个 DaemonSet 组件 Koordlet 组成。Koordinator 在 Kubernetes 原有的能力基础上增加了混部功能,并兼容了 Kubernetes 原有的工作负载。
Koordinator Scheduler
Koordinator Scheduler 以 Deployment 的形式部署,用于增强 Kubernetes 在混部场景下的资源调度能力,包括:
- 更多的场景支持,包括弹性配额调度、资源超卖、资源预留、Gang 调度、异构资源调度
- 更好的性能,包括动态索引优化、等价 class 调度、随机算法优化
- 更安全的 descheduling,包括工作负载感知、确定性的 Pod 迁移、细粒度的流量控制和变更审计支持
Koordinator Manager
Koordinator Manager 以 Deployment 的形式部署,通常由两个实例组成,一个 leader 实例和一个 backup 实例。Koordinator Manager 由几个控制器和 webhooks 组成,用于协调混部场景下的工作负载,资源超卖和 SLO 管理。
目前,提供了三个组件:
- Colocation Profile,用于支持混部而不需要修改工作负载。用户只需要在集群中做少量的配置,原来的工作负载就可以在混部模式下运行
- SLO 控制器,用于资源超卖管理,根据节点混部时的运行状态,动态调整集群的超发配置比例。该控制器的核心职责是管理混部时的 SLO,如智能识别出集群中的异常节点并降低其权重,动态调整混部时的水位和压力策略,从而保证集群中 Pod 的稳定性和吞吐量
- Recommender,它使用 histograms 来统计和预测工作负载的资源使用细节,用来预估工作负载的峰值资源需求,从而支持更好地分散热点,提高混部的效率。此外,提供资源画像功能,预估工作负载的峰值资源需求,资源 profiling 还将用于简化用户资源规范化配置的复杂性,如支持 VPA
Koordlet
Koordlet 以 DaemonSet 的形式部署在 Kubernetes 集群中,用于支持混部场景下的资源超卖、干扰检测、QoS 保证等。
在 Koordlet 内部,它主要包括以下模块:
- 资源 profiling,估算 Pod 资源的实际使用情况,回收已分配但未使用的资源,用于低优先级 Pod 的 overcommit
- 资源隔离,为不同类型的 Pod 设置资源隔离参数,避免低优先级的 Pod 影响高优先级 Pod 的稳定性和性能
- 干扰检测,对于运行中的 Pod,动态检测资源争夺,包括 CPU 调度、内存分配延迟、网络、磁盘 IO 延迟等
- QoS 管理器,根据资源剖析、干扰检测结果和 SLO 配置,动态调整混部节点的水位,抑制影响服务质量的 Pod
- 资源调优,针对混部场景进行容器资源调优,优化容器的 CPU Throttle、OOM 等,提高服务运行质量
弹性资源配置
1 | apiVersion: v1 |
开启后动态资源后,可以看到节点已经识别到扩展资源 kubernetes.io/batch-cpu 与 kubernetes.io/batch-memory。
1 | kubectl describe node wnx |
mutating webook 注入的信息是根据 ClusterColocationProfile 决定的:
1 | apiVersion: config.koordinator.sh/v1alpha1 |
模拟在离线服务混部
1 | apiVersion: v1 |
在节点剩余 4C 左右的资源时,通过离线服务使用超卖资源、在线服务使用标准资源的混部模式,可以让服务均成功部署在节点上。
1 | kubectl get pod |
弹性资源限制
虽然离线服务的 cgroup 还是位于 kubepods 的 besteffort 组中(由于原本声明的标准资源被 webhook 变更为扩展资源,也就变成了 BestEffort QoS 的 Pod),但是 Koordlet 会根据扩展资源的声明规格手动维护。
1 | cat /sys/fs/cgroup/cpu/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pod4bb9f204_6690_43cf_a871_808874ad0ed4.slice/cpu.cfs_quota_us |
此外,在离线服务所使用的 CPU 是有区别的
1 | BE QoS Pod 使用的 CPU 为 0-4 |
并且,随着节点负载上升(通过在线服务容器 stress 进程模拟),节点中可用的弹性资源(capacity 与 allocatable)也会逐渐变少,离线服务使用的 CPU 也会相应的缩减,但是不会停止离线服务。
1 | cat /sys/fs/cgroup/cpuset/kubepods/besteffort/podcee106b7-48ff-4441-9bba-b37c0e4620f9/ef02220e4d28ff6ebd8768ac55a4f73b22b80fac5321f1acbde35acebaa1a74f/cpuset.cpus |
「 Kubernetes 」节点资源超卖
http://shenxianghong.github.io/2023/06/13/2023-06-13 Kubernetes 节点资源超卖/